- [10분 테코톡] 큰곰 & 소니의 캐시를 보며 정리한 내용입니다.
캐시(CACHE)
목차
[브라우저 캐시](##브라우저 캐시?)
메모리 계층 구조
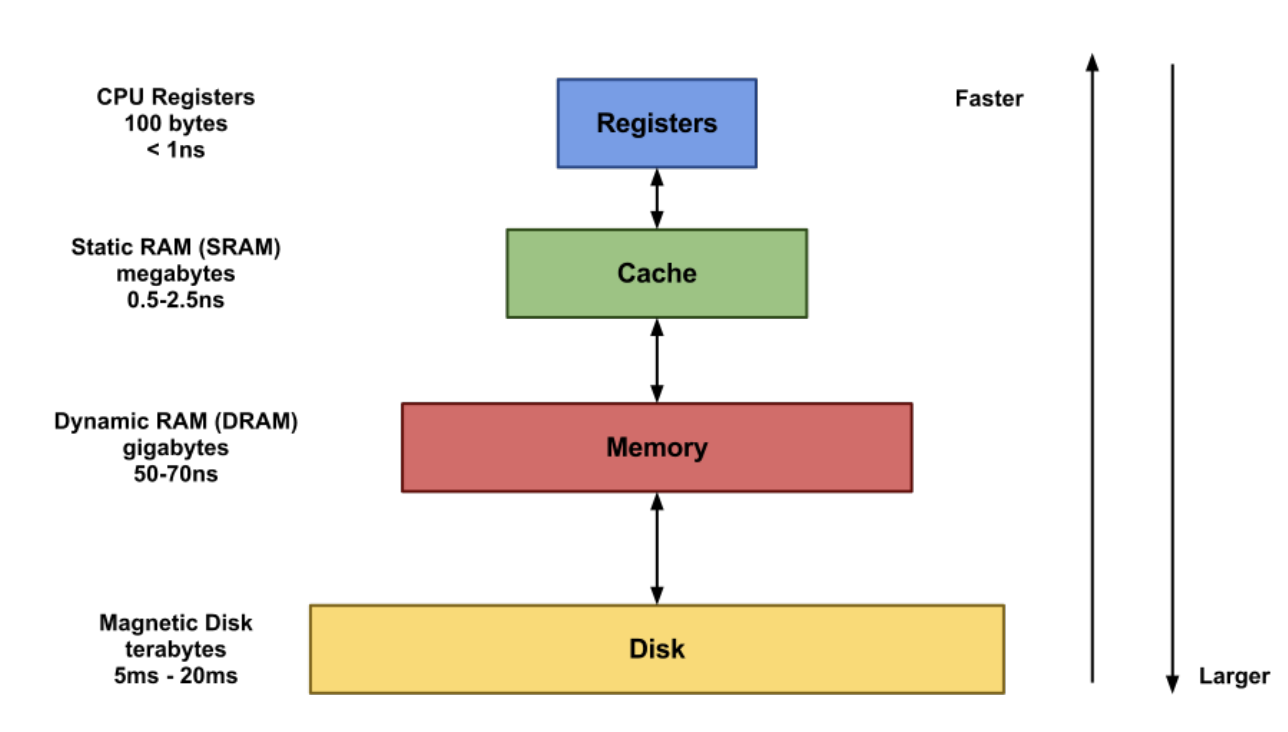
계층이 높아질수록 속도가 빠르지만 용량은 적다.
반대로 계층이 낮아질수록 속도는 느리지만 용량은 많다.
데이터를 저장하는 공간의 속도와 용량은 반비례 관계
속도가 빠른 메모리일수록 용량이 작음 - RAM이 SSD나 HDD보다 용량이 작지만 속도가 빠름
용량이 큰 저장장치는 속도가 느림 - RAM 보다 SSD나 HDD가 용량이 크지만 속도가 느림
둘 다 잡기에는 비용이 너무 많이 든다
그래서 데이터 저장 공간은 속도와 용량에 따라 특성에 맞게 역할을 나누어서 사용한다.
데이터 저장 공간을 속도-용량 순서대로 쌓으면 피라미트와 같은 계층구조가 나온다(Memory hierarchy)
파레토의 법칙
- 이탈리아의 경제학자 빌브레도 파레토가 발견한 현상
- 원인중 상위 20%가 전체 80%를 만든다는 법칙 - 2:8 법칙
- 여러곳에서 관찰할 수 있다.
- 인구의 20%가 전체 부의 80%를 가짐
- 잘 팔리는 제품 20%가 매출의 80%를 차지
- 많이 쓰이는 단어 20%가 언어 사용빈도의 80%를 차지
데이터 지역성의 원리
자주 쓰이는 데이터는 시간적 혹은 공간적으로 한 곳에 몰려 있을 가능성이 높다
시간 지역성 (Temporal Locality)
- 예를 들어 for문에서 조건 변수(int i = 0)을 선언했을 때, 해당 변수는 for문이 끝나기 전 까지 계속 쓰일 확률이 높다.
공간 지역성(Spatial Locality):
- 예를들어 for문에서 어떤 배열에 접근했을 때, 해당 배열이 위치한 메모리
공간의 내용은 for문이 끝나기 전까지는 계속 쓰일 확률이 높다.
- 예를들어 for문에서 어떤 배열에 접근했을 때, 해당 배열이 위치한 메모리
순차 지역성(Seuquential Locality)
- for문 배열에서 array[0], array[1] 같이 배열에 순차적으로 접근할 때 다음 번에는 array[2]에 접근할 확률이 높은것
캐시(Cache)
사전적 정의 : 나중에 필요할 수도 있는 무언가를 저장하였다가, 신속하게 회수할 수 있는 보관장소
어떤 식으로든 보호되거나 숨겨진다.
캐시의 작동 방식
아주 빠르게 접근할 수 있는 메모리 공간에, 원본 데이터(System-of-Record)와는 별개로 자주 쓰이는 데이터들을 복사해 둘 캐시 공간을 마련한다.
- 캐시 공간은 상수시간 [O(1)]등 낮은 시간 복잡도로 접근 가능한 곳을 주로 사용한다.
데이터를 달라는 요청을 들어오면, 원본 데이터가 담긴 곳에 접근하기
전에먼저 캐시 내부에서 부터 찾는다.캐시에 원하는 데이터가 없거나(Cache miss라고 한다.) 너무 오래되어 최신성을 잃었으면(Expiration) 그때서야 원본 데이터가 있는 곳에 접근하여 데이터를 가져온다.
- 이때 데이터를 가져오면서 캐시에도 해당 데이터를 복사하거나, 갱신한다
캐시에 원하는 데이터가 있으면 원본 데이터가 있는 공간에 접근하지 않고 바로 캐시에서 해당 데이터를 제공한다.(Cache Hit 라고 한다)
캐시 공간은 작으므로, 공간이 모자라게 되면 안 쓰는 데이터부터 삭제하여 공간을 확보한다.
캐시가 쓰이는 사례
CPU의 캐시 메모리
- 현대의 CPU는 1초에 최고 수십억번 작동 가능.
- 아무리 빠른 주 기억장치라도 CPU를 따라가긴 어렵다.
- 그래서 SRAM이라는 특수한 메모리를 CPU에 내장해 캐시 메모리로 사용
- 현대의 CPU는 1초에 최고 수십억번 작동 가능.
하드디스크. 데이터베이스
하드디스크는 주기억장치에 비해 10만배 이상 느린 장치.
- 처리 효율을 올리려면 자주 쓰이는 데이터를 캐싱해두는 것이 좋다.
데이터 베이스도 쿼리를 실행하여 하드디스크에서 데이터를 읽고 쓰는 것은 시간이 오래걸리는 작업이다.
대게 데이터베이스는 쓰기보다는 읽기가 많으므로, 자주 요청받는 쿼리의 결과를 캐싱해두면 효율이 오른다.
따라서 데이터베이스 자체에서 별도의 캐시를 운영한다.
JPA의 영속성 컨텍스트(Persistence context)도 캐시의 일종이다
CDN (Content Delivery Netowrk)
한국에 있는 사용자가 미국에 있는 YouTube 콘텐츠의 자원을 요청하면 물리적 네트워크 거리 때문에 속도가 느리다.
각 지역마다 콘텐츠들의 캐시 서버를 두면, 물리적으로도 거리가 짧아지므로 전송속도를 높이고 부하를 분산시킬 수 있다.
CDN은 클라이언트와 웹 사이트 서버 간에 중간 서버를 두어 효율성을 높인다.
웹 서버에 대한 웹 트래픽을 줄이고, 대역폭 소비를 줄이며, 애플리케이션의 사용자 환경을 개선합니다.
- 웹 캐시
- 네트워크를 통해 데이터를 가져오는 것은 하드디스크보다도 느릴 때가 많다.
- 네트워크 사정에 따라 정말 다양하다.
- 그래서 웹 브라우저는 웹 페이지에 접속할 때 HTML, CSS, JS, Image 등을 하드디스크나 메모리에 캐싱해뒀다가 다음 번에 다시 접속할 때 이를 재활용 한다 -
브라우저 캐시 - 웹 서버 또한 상당수의 경우 동적 웹 페이지라 할지라도 매번 내용이 바뀌지 않는 경우가 더많다.
- 서버에서 생성한 HTML을 캐싱해뒀다가 다음 번 요청에 이를 재활용 한다 -
응답 캐시
- 서버에서 생성한 HTML을 캐싱해뒀다가 다음 번 요청에 이를 재활용 한다 -
- 클라이언트에서 자주 요청받는 내용은 웹 서버로 전달하지 않고, 웹 서버 앞단의 프록시 서버에서 캐싱해둔 데이터를 바로 제공하기도 한다. -
프록시 캐시
- 네트워크를 통해 데이터를 가져오는 것은 하드디스크보다도 느릴 때가 많다.
브라우저 캐시?
웹 서버에서
클라이언트에 보내는 HTTP 헤더에 캐시 지시자를 삽입하면, 클라이언트 웹 브라우저에서는 해당 지시자에 명시된 캐시 정책에 따라 캐싱을 실시한다.캐시의 유효 시간(max-age)이 지나도 캐시된 데이터가 바뀌지 않은 경우를 확인하기 위해 Etag라는 유효성 검사 토큰을 사용한다.
Cache-Control: max-age = 3600 // 초단위이다
Etag: 데이터에 대한
Hash값인 유효성 검사 토큰- 이 식별자가 같다면 리소스가 바뀌지 않았다는 것이므로 다운로드를 건너뛸 수 있다.- 서버에서 리소스 조회 요청에 대해 Etag HTTP 헤더로 유효성 검사 토큰 전달 (클라이언트는 내용 알 필요 없다.)
- 브라우저 캐시 내 리소스가 만료되면 Etag를 요청에 실어 서버로 보내 리소스가 변경되었는지 확인
- Etag 값이 다르면 변경사항이 있는 것이므로 서버는 업데이트된 리소스와 새로운 Etag 값을 반환
때로는 캐시 유효 시간을 최대한 길게 잡으면서도 static 파일의 업데이트를 신속히 적용하기 위해 정적 파일의 이름 뒤에 별도의 토큰이나 버전 번호를 붙여야 하는 경우도 있다.
조회가 반복된다면, Cache-Controler, ETag, 버전관리를 함께 사용하여 캐시를 효율적으로 사용하는게 좋다.
Redis?
Redis : Remote Dictronary Server
메모리 기반 오픈소스 NoSQL DBMS의 일종으로, 캐싱을 위해 많이 쓴다.
여기서 Dictionary는 Java의 HashMap<Key, Value> 파이썬의 Dictionary를 생각하면 된다.
- 기본적으로 모든 데이터를 메모리에 저장하여 처리하므로 속도가 빠르다.
- 비용은 비싼 단점이 있다.
- 서버 재부팅 때 메모리의 데이터가 휘발되지 않게끔 데이터를 하드디스크에 기록할 수 있다.
- 캐시나, 램은 휘발성 메모리이다.
- DBMS의 일종이므로 명시적으로 삭제하지 않는 한 메모리에서 데이터를 삭제하지 않는다.
- 자체적으로 여러가지 자료형을 지원한다.
Java에서는 캐싱할 때 보통 뭐 써요? - EHcashe
- Java의 표준 캐싱 API 명세인 JSR-107을 따르는 오픈소스 캐시 구현체
- Spring 프레임워크나 Hibernate ORM 등에서 바로 사용 가능
- Java진영에서 가장 널리 쓰인다고 한다
- 캐시 저장공간을 속도에 따라 여러 등급(Tier)으로 나누어 메모리 계층 구조를 적용 가능
- 메모리에 캐시된 내용을 하드디스크에 기록 가능
- 대규모 서비스에서 캐시 서버 여럿을 클러스터로 묶을 수 있는 기능을 제공
서비스의 모든 단계에 들어가는 캐시들
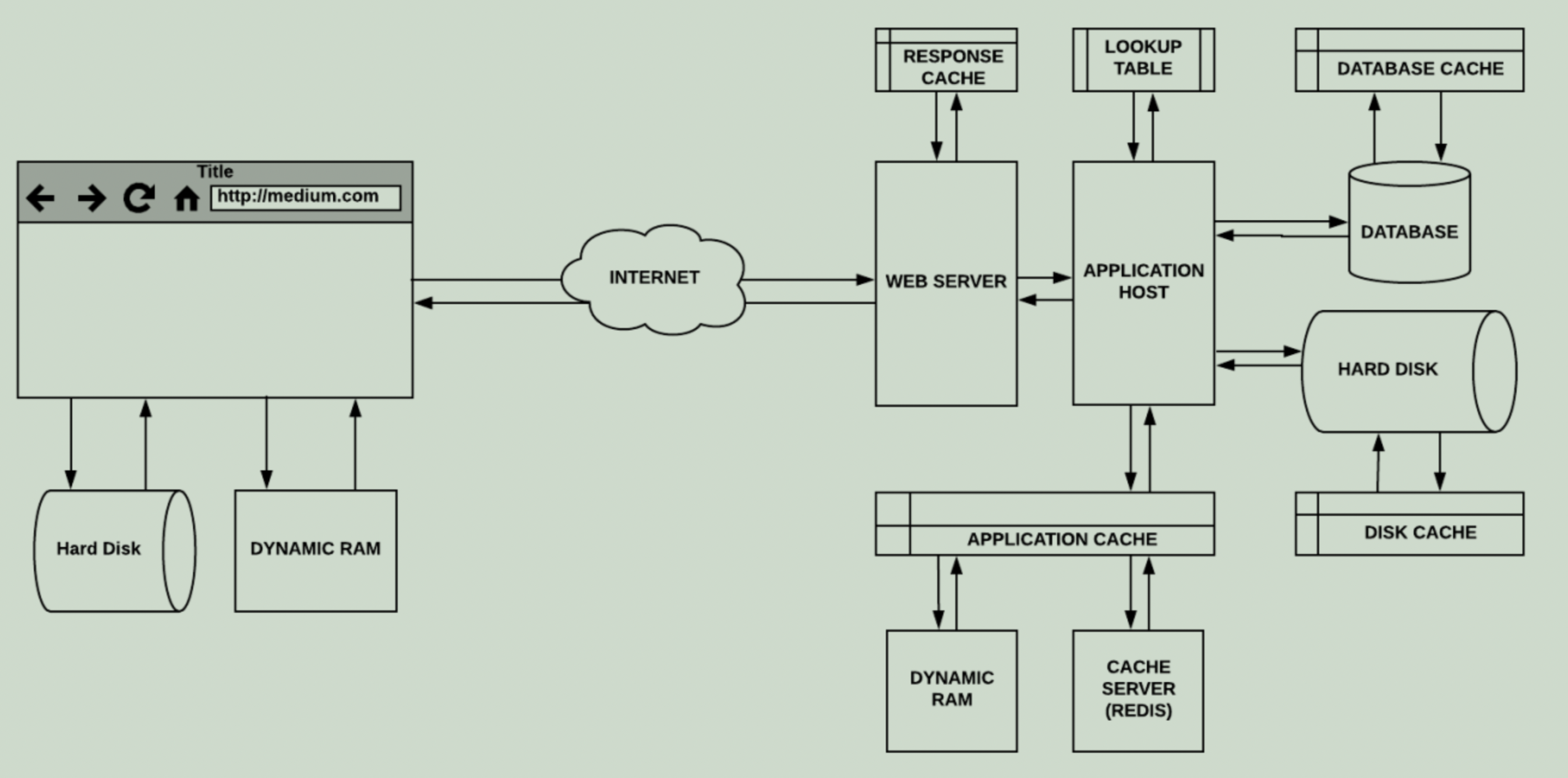
원문 : https://blog.codeanalogies.com/2018/06/11/web-cachingexplained-by-buying-milk-at-the-supermarket/
번역 : https://rinae.dev/posts/web-caching-explained-by-buying-milk-kr
Spring Boot Cache
Spring Boot Cache - @Cacheable
build.gradle에 의존성 추가
implementation 'org.springframework.boot:spring-boot-stater-cache'Configuration Class나 Main Class에 @EnableCaching 어노테이션 추가
import org.springframework.cache.annotation.EnableCaching;
@EnableCaching
public class CacheConfig {
...
}
@Service
@RequiredArgsConstructor
public class BookService {
private final BookRepository bookRepository;
public Book saveBook(Book book) {
return bookRepository.save(book);
}
@Cacheable(value = "book") // 사용
public Book get(Long id) {
return bookRepository.findById(id);
}
@CachePut(value = "book", key = "#book.id")
public Book update(Book book) {
if (bookRepository.existsById(book.getId())) {
return bookRepository.save(book);
}
...
}
@CacheEvict(value = "book", key = "#id")
public void delete(Long id) {
bookRepository.deleteById(id);
}
}
- @Cacheable(value = "book")
- 서버의 메모리에
book이라는 해시테이블을 만들고, key 값은Long idvalue 는Book으로 해서 데이터를 저장
- 서버의 메모리에
- 첫번 째 조회를 할 때는 findbyId로 데이터를 DB에서 가져오고,
- 두번 째 요청부터는 Cache 에서 가져오게 된다.
- @CachePut(valuue = "book", key = "#book.id")
- 데이터가 업데이트 된다면 캐시에 저장된 값도 바뀌어야 한다.
- 이 어노테이션으로 캐시된 데이터를 업데이트 해준다
- @CacheEvict(value = "book", key = "#id")
- 캐시에 저장된 데이터를 삭제
참조
'하루한개 > 우아한 테크코스-10분테코톡' 카테고리의 다른 글
| 데이터베이스 락 (Database Lock, DB Lock) (0) | 2022.09.03 |
|---|---|
| 정규표현식 and With Java (0) | 2022.08.31 |
| Spring vs Spring boot (0) | 2022.08.21 |
| MVC 패턴 , 5 Layer 패턴 (0) | 2022.08.19 |
| DTO vs VO 그리고 Entity (0) | 2022.08.15 |