JPA 프로그래밍 스터디 7장 정리
7장 고급 매핑
✅ 7.1 상속 관계 매핑
관계형 데이터베이스에는 객체지향 언어에서 다루는 상속이라는 개념이 없다.
대신 슈퍼타입 서브타입 관계(Super-Type Sub-Type Relationship)라는 모델링 기법이 객체의 상속 개념과 가장 유사하다.

슈퍼타입 서브타입 논리 모델을 실제 물리 모델인 테이블로 구현할 때는 3가지 방법을 선택할 수 있다.
(조인 전략): 각각의 테이블로 변환 - 모두 테이블로 만들고 조회할 때 조인을 사용단일 테이블 전략: 통합 테이블로 변환 - 테이블을 하나만 사용해서 통합구현 클래스마다의 테이블 전략: 서브타입 테이블로 변환 - 서브 타입마다 하나의 테이블을 추가한다.
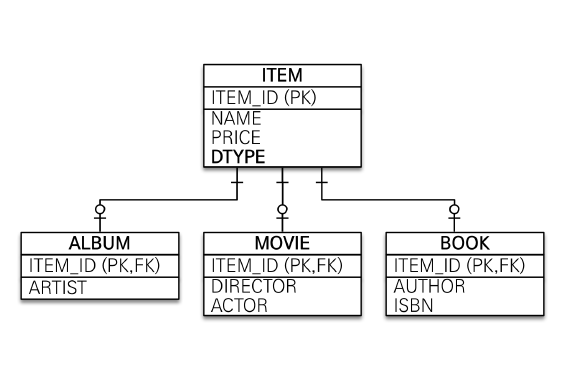
🔸 7.1.1 조인 전략 (JOINED)
- 조인 전략은 엔티티 각각을 모두 테이블로 만들고 자식 테이블이 부모 테이블의 기본키를 받아서 기본 키 + 외래 키로 사용하는 전략이다.
- 따라서 조회할 때 조인을 자주 사용한다.
- 이 전략을 사용할 때 주의할 점이 있는데 객체는 타입으로 구분할 수 있지만 테이블은 타입의 개념이 없다.
- 그러므로, 테이블의 컬럼을 구분할 타입 데이터가 필요하다.
- 타입을 구분하는 컬럼을 추가해야 한다.
- Enum 등을 이용할 수 있다.
- 여기서는 DTYPE 컬럼을 구분 컬럼으로 사용한다.
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "DTYPE")
public abstract class Item {
@Id @GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
}
@Entity
@DiscriminatorValue("A")
public class Album extends Item {
private String artist;
}
@Entity
@DiscriminatorValue("M")
public class Movie extends Item {
private String director;
private String actor;
}
@Inheritance 어노테이션
- 상속 매핑 (상속받는 엔티티들이 받을 옵션들)은 부모 클래스에 @Inheritance 어노테이션을 달아야 한다.
@Inheritance 어노테이션의 옵션들 - 상속 매핑 전략
@Inheritance(strategy = InheritanceType.JOINED)InheritanceType.JOINED: 조인 전략시 사용- 하위 클래스에 특정한 필드를 상위 클래스에 공통된 필드와 별도의 테이블에 매핑하고 조인을 수행하여 하위 클래스를 인스턴스화하는 전략
InheritanceType.TABLE_PER_CLASS: 상위 엔티티의 공통 속성들을 모두 하위 엔티티로 내려 각각의 테이블로 만드는 전략InheritanceType.SINGLE_TABLE: 테이블을 하나만 사용하고, 구분 컬럼(DTYPE)으로 어떤 자식 데이터가 저장되었는지 구분- default 전략
@DiscriminatorColumn(name = "DTYPE")- 부모 클래스에 구분 컬럼을 지정한다. 이 컬럼으로 저장된 자식 테이블을 구분할 수 있다.
- 기본값이 DTYPE 이므로
@DiscriminatorColumn으로 줄여 사용해도 된다.
@DiscriminatorValue("M")- 엔티티를 저장할 때 구분 컬럼에 입력할 값을 지정한다.
- 만약 영화 엔티티를 저장하면 구분 컬럼인 DTYPE에 값 M이 저장된다.
기본값으로 자식 테이블은 부모 테이블의 ID 컬럼명을 그대로 사용하는데, 만약 자식 테이블의 기본 키 컬럼명을 변경하고 싶으면 자식 테이블에서 @PrimaryKeyJoinColumn 어노테이션을 사용하면 된다.
@Entity
@DiscriminatorValue("B")
@PrimaryKeyJoinColumn(name = "BOOK_ID")
public class Book extends Item {
private String author;
private String isbn;
}- 장점
- 테이블이 정규화된다.
- 외래 키 참조 무결성 제약조건을 활용할 수 있다.
- 저장공간을 효율적으로 사용한다.
- 단점
- 조회할 때 조인이 많이 사용되므로 성능이 저하될 수 있다.
- 조회 쿼리가 복잡하다.
- 데이터를 등록할 INSERT SQL을 두 번 실행한다.
- 특징
- JPA 표준 명세는 구분 컬럼을 사용하도록 하지만, 하이버네이트를 포함한 몇몇 구현체는 구분 컬럼(
@DiscriminatorColumn)없이 동작한다.
- JPA 표준 명세는 구분 컬럼을 사용하도록 하지만, 하이버네이트를 포함한 몇몇 구현체는 구분 컬럼(
🔸 7.1.2 단일 테이블 전략 (SINGLE_TABLE)
단일 테이블 전략은 이름 그대로 테이블을 하나만 사용한다.
그리고 구분 컬럼으로 어떤 자식 데이터가 저장되었는지 구분한다.
조회할 때 조인을 사용하지 않으므로 일반적으로 가장 빠르다.

이 전략을 사용할 때 주의점은 자식 엔티티가 매핑한 컬럼은 모두 null을 허용해야 한다는 점이다.
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "DTYPE")
public abstract class Item {
@Id @GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
}
@Entity
@DiscriminatorValue("A")
public class Album extends Item {}
@Entity
@DiscriminatorValue("M")
public class Movie extends Item {}
@Entity
@DiscriminatorValue("B")
public class Book extends Item {}
InheritanceType.SINGLE_TABLE로 지정하면 단일 테이블 전략을 사용한다.
- 장점
- 조인이 필요 없으므로 일반적으로 조회 성능이 빠르다.
- 조회 쿼리가 단순하다.
- 단점
- 자식 엔티티가 매핑한 컬럼은 모두 null을 허용해야 한다.
- 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 그러므로 상황에 따라서는 조회 성능이 오히려 느려질 수 있다.
- 특징
- 구분 컬럼을 꼭 사용해야 한다. 따라서
@DiscriminatorColumn을 꼭 설정해야한다. @DiscriminatorValue를 지정하지 않으면 기본으로 엔티티 이름을 사용한다.
- 구분 컬럼을 꼭 사용해야 한다. 따라서
🔸 7.1.3 구현 클래스마다 테이블 전략 (TABLE_PER_CLASS)
구현 클래스마다 테이블전략은 자식 엔티티마다 테이블을 만든다.

@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public abstract class Item {
@Id @GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
}
@Entity
public class Album extends Item {}
@Entity
public class Movie extends Item {}
@Entity
public class Book extends Item {}
InheritanceType.TABLE_PER_CLASS를 선택하면 구현 클래스마다 테이블 전략을 사용한다. 이 전략은 자식 인테테마다 테이블을 만든다.
- 장점
- 서브 타입을 구분해서 처리할 때 효과적이다.
- not null 제약조건을 사용할 수 있다.
- 단점
- 여러 자식 테이블을 함께 조회할 때 성능이 느리다.
- 자식 테이블을 통합해서 쿼리하기 어렵다.
- 특징
- 구분 컬럼을 사용하지 않는다.
✅ 7.2 @MappedSuperclass
부모 클래스는 테이블과 매핑하지 않고 부모 클래스를 상속 받는 자식 클래스에게 매핑 정보만 제공하고 싶으면 @MappedSuperclass를 사용하면 된다.
@MappedSuperclass는 비유를 하자면 추상 클래스와 비슷한데 @Entity는 실제 테이블과 매핑되지만 @MappedSuperclass는 실제 테이블과는 매핑되지 않는다.
회원(Member)과 판매자(Seller)는 서로 관계가 없는 테이블과 엔티티다.
테이블은 그대로 두고 객체 모델의 id, name 두 공통 속성을 부모 클래스로 모으고 객체 상속 관계로 만든다면,
@MappedSuperclass
public abstract class BaseEntity{
@Id @GeneratedValue
private Long id;
private String name;
}
@Entity
public class Member extends BaseEntity {
private String email
}
@Entity
public class Seller extends BaseEntity {
private String shopName;
}
BaseEntity에는 객체들이 주로 사용하는 공통 매핑 정보를 정의했다. 그리고 자식 엔티티들은 상속을 통해 물려받았다.
여기서 BaseEntity는 테이블과 매핑할 필요가 없고 자식 엔티티에게 공통으로 사용되는 매핑 정보만 제공하면 된다. 따라서 @MappedSuperclass를 사용했다.
부모로부터 물려받은 매핑 정보를 재정의하고자 한다면,
// 부모에게 상속받은 id 속성의 컬럼명을 MEMBER_ID로 재정의했다.
@Entity
@AttributeOverride(name = "id", column = @Column(name = "MEMBER_ID"))
public class Member extends BaseEntity {}
// 둘 이상을 재정의하려면,
@Entity
@AttributeOverrides({
@AttributeOverride(name = "id", column = @Column(name = "MEMBER_ID")),
@AttributeOverride(name = "name", column = @Column(name = "MEMBER_NAME"))
})
public class Member extends BaseEntity {}
@MappedSuperclass의 특징
- 테이블과 매핑되지 않고 자식 클래스에 엔티티의 매핑 정보를 상속하기 위해 사용한다.
@MappedSuperclass로 지정한 클래스는 엔티티가 아니므로em.find()나 JPQL에서 사용할 수 없다.- 이 클래스를 직접 생성해서 사용할 일은 거의 없으므로 추상 클래스로 만드는 것을 권장한다.
✅ 7.3 복합 키와 식별 관계 매핑
복합 키(Composite Key)란?
데이터를 대표하는 키가 여러 개의 컬럼으로 구성된 것을 의미
🔸 7.3.1 식별 관계 vs 비식별 관계
식별 관계란?
부모 테이블의 기본 키를 내려받아서 자식 테이블의 기본 키 + 외래 키로 사용하는 관계

비식별 관계?
부모 테이블의 기본 키를 받아서 자식 테이블의 외래 키로만 사용하는 관계다.

🔸 7.3.2 복합 키: 비식별 관계 매핑
@Entity
public class Hello {
@Id
private String id1;
@Id
private String id2;
// Composite-id class must implement Serializable 에러 발생
}둘 이상의 컬럼으로 구성된 복합 기본 키는 다음처럼 매핑하면 될 것 같지만 막상 해보면 매핑 오류가 발생한다.
JPA에서 식별자를 둘 이상 사용하려면 별도의 식별자 클래스를 만들어야 한다.
@IdClass

PARENT 테이블을 보면 기본 키를 PARENT_ID1, PARENT_ID2로 묶은 복합 키로 구성
@Entity
@IdClass(ParentId.class)
public class Parent {
@Id
@Column(name = "PARENT_ID1")
private String id1;
@Id
@Column(name = "PARENT_ID2")
private String id2;
private String name;
}
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor
@EqualsAndHashCode
public class ParentId implements Serializable {
private String id1;
private String id2;
}@IdClass를 사용할 때 식별자 클래스는 다음 조건을 만족해야 한다.
- 식변자 클래스의 속성명과 엔티티에서 사용하는 식별자의 속성명이 같아야 한다.
Serializable인터페이스를 구현해야 한다.equals,hashCode를 구현해야 한다.- 기본 생성자가 있어야 한다.
- 식별자 클래스는 public 이어야 한다.
@Test
void idClassTest(){
// given
Parent parent = new Parent();
parent.setId1("id1");
parent.setId2("id2");
parent.setName("parentName");
em.persist(parent);
// when
ParentId parentId = new ParentId("id1", "id2");
Parent findParent = em.find(Parent.class, parentId);
// then
assertThat(parent).isEqualTo(findParent);
}
이제 Child를 추가
@Entity
public class Child {
@Id
private String id;
@ManyToOne
@JoinColumns({
@JoinColumn(name = "PARENT_ID1", referencedColumnName = "PARENT_ID1"),
@JoinColumn(name = "PARENT_ID2", referencedColumnName = "PARENT_ID2")
})
private Parent parent;
}부모 테이블의 기본 키 컬럼이 복합 키이므로 자식 테이블의 외래 키도 복합 키이다.
따라서 외래 키 매핑 시 여러 컬럼을 매핑해야 하므로 @JoinColumns를 사용하고 각각 외래 키 컬럼을 @JoinColumn으로 매핑한다.
@EmbeddedId
@IdClass가 데이터베이스에 맞춘 방법이라면 @EmbeddedId는 좀 더 객체지향적인 방법
@Entity
public class ParentV2 {
@EmbeddedId
private ParentIdV2 id;
private String name;
}
@Embeddable
@EqualsAndHashCode
public class ParentIdV2 implements Serializable {
@Column(name = "PARENT_ID1")
private String id1;
@Column(name = "PARENT_ID2")
private String id2;
}@IdClass와는 다르게 @EmbeddedId를 적용한 식별자 클래스는 식별자에 기본 키를 직접 매핑한다. @EmbeddedId를 적용한 식별자 클래스는 다음 조건을 만족해야 한다.
@EmbeddedId를 붙여주어야 한다.Serializable인터페이스를 구현해야 한다.equals,hashCode를 구현해야 한다.- 기본 생성자가 있어야 한다.
- 식별자 클래스는 public 이어야 한다.
@Test
void embeddedIdTest(){
// given
ParentV2 parentV2 = new ParentV2();
ParentIdV2 idV2 = new ParentIdV2("id1", "id2");
parentV2.setId(idV2);
parentV2.setName("parentV2Name");
em.persist(parentV2);
// when
ParentIdV2 parentId = new ParentIdV2("id1", "id2");
ParentV2 findParentV2 = em.find(ParentV2.class, parentId);
// then
assertThat(parentV2).isEqualTo(findParentV2);
}
- 복합 키와 equals(), hashCode()
영속성 컨텍스트는 엔티티의 식별자를 키로 사용해서 엔티티를 관리한다. 그리고 식별자를 비교할 때 equals, hashCode를 사용한다.
따라서, 식별자 객체의 동등성이 지켜지지 않으면 예상과 다른 엔티티가 조회되거나 엔티티를 찾을 수 없는 등 영속성 컨텍스트가 엔티티를 관리하는 데 심각한 문제가 발생한다.
@IdClassvs@EmbeddedId
각각 장단점이 있으므로 본인의 취향에 맞는 것을 일관성 있게 사용하면 된다. @EmbeddedId가 @IdClass와 비교해서 더 객체지향적이고 중복도 없어서 좋아보이긴 하지만 특정 상황에 JPQL이 조금 더 길어질 수 있다.
🔸 7.3.3 복합 키: 식별 관계 매핑

부모, 자식, 손자까지 계속 기본 키를 전달하는 식별 관계에서 자식 테이블은 부모 테이블의 기본 키를 포함해서 복합 키를 구성해야 하므로 @IdClass나 @EmbeddedId를 사용해서 식별자를 매핑해야 한다.
@IdClass를 이용한 매핑
@Data
@Entity
public class ParentV3 {
@Id
@Column(name = "PARENT_ID")
private String id;
private String name;
}
@Entity
@IdClass(ChildIdV3.class)
public class ChildV3 {
@Id
@ManyToOne
@JoinColumn(name = "PARENT_ID")
public ParentV3 parentV3;
@Id
@Column(name = "CHILD_ID")
private String childId;
private String name;
}
@EqualsAndHashCode
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor
public class ChildIdV3 implements Serializable {
private ParentV3 parentV3;
private String childId;
}
@Entity
@IdClass(GrandChildId.class)
public class GrandChild {
@Id
@ManyToOne
@JoinColumns({
@JoinColumn(name = "PARENT_ID"),
@JoinColumn(name = "CHILD_ID")
})
private ChildV3 childV3;
@Id
@Column(name = "GRANDCHILD_ID")
private String id;
private String name;
}
@EqualsAndHashCode
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor
public class GrandChildId implements Serializable {
private ChildV3 childV3;
private String id;
}
@EmbeddedId를 이용한 매핑
@Entity
public class ParentV4 {
@Id @Column(name = "PARENT_ID")
private String id;
private String name;
}
@Entity
public class ChildV4 {
@EmbeddedId
private ChildIdV4 id;
@MapsId("parentId")
@ManyToOne
@JoinColumn(name = "PARENT_ID")
public ParentV4 parentV4;
}
@EqualsAndHashCode
@NoArgsConstructor
@AllArgsConstructor
@Embeddable
public class ChildIdV4 implements Serializable {
private String parentId;
@Column(name = "CHILD_ID")
private String id;
}
@Entity
public class GrandChildV2 {
@EmbeddedId
private GrandChildIdV2 id;
@MapsId("childId")
@ManyToOne
@JoinColumns({
@JoinColumn(name = "PARENT_ID"),
@JoinColumn(name = "CHILD_ID")
})
private ChildV4 childId;
private String name;
}
@EqualsAndHashCode
@Embeddable
public class GrandChildIdV2 implements Serializable {
private ChildIdV4 childId;
@Column(name = "GRANDCHILD_ID")
private String id;
}@EmbeddedId는 식별 관계로 사용할 연관관계의 속성에 @MapsId를 사용하면 된다.
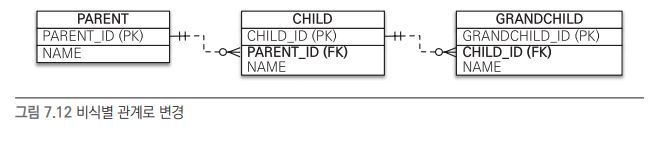
🔸 7.3.4 비식별 관계로 구현
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
}
@Entity
public class Child {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "PARENT_ID")
private Parent parent;
}
@Entity
public class GrandChild {
@Id @GeneratedValue
@Column(name = "GRANDCHILD_ID")
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "CHILD_ID")
private Child child;
}식별 관계의 복합 키를 사용한 코드와 비교하면 매핑도 쉽고 코드도 단순하다. 그리고 복합 키가 없으므로 복합 키 클래스를 만들지 않아도 된다.
🔸 7.3.5 일대일 식별 관계

@Entity
public class Board {
@Id @GeneratedValue
@Column(name = "BOARD_ID")
private Long id;
private String title;
@OneToOne(mappedBy = "board")
private BoardDetail boardDetail;
}
@Entity
public class BoardDetail {
@Id
private Long boardId;
@MapsId
@OneToOne
@JoinColumn(name = "BOARD_ID")
private Board board;
private String content;
}BoardDetail처럼 식별자가 단순히 컬럼 하나면 @MapsId를 사용하고 속성 값은 비워두면 된다.
이때 @MapsId는 @Id를 사용해서 식별자로 지정한 BoardDetail.boardId와 매핑된다.
🔸 7.3.6 식별, 비식별 관계의 장단점
데이터베이스 설계 관점에서 보면 다음과 같은 이유로 식별 관계보다는 비식별 관계를 선호한다.
- 식별 관계는 부모 테이블의 기본 키를 자식 테이블로 전파하면서 자식 테이블의 기본 키 컬럼이 점점 늘어난다.
- 식별 관계는 2개 이상의 컬럼을 합해서 복합 기본 키를 만들어야 하는 경우가 많다.
- 식별 관계를 사용할 때 기본 키로 비즈니스 의미가 있는 자연 키 컬럼을 조합하는 경우가 많다. 반면에 비식별 관계의 기본 키는 비즈니스와 전혀 관계없는 대리 키를 주로 사용한다.
- 식별 관계는 부모 테이블의 기본 키를 자식 테이블의 기본 키로 사용하므로 비식별 관계보다 테이블 구조가 유연하지 못하다.
- 일대일 관계를 제외하고 식별 관계는 2개 이상의 컬럼을 묶은 복합 기본 키를 사용한다. JPA에서 복합 키는 별도의 복합 키 클래스를 만들어서 사용해야 한다.
- 비식별 관계의 기본 키는 주로 대리 키를 사용하는데 JPA는
@GeneratedValue처럼 대리 키를 생성하기 위한 편리한 방법을 제공한다.
물론 식별 관계가 가지는 장점도 있다. 기본 키 인덱스를 활용하기 좋고, 상위 테이블들의 기본 키 컬럼을 자식, 손자 테이블들이 가지고 있으므로
특정 상황에 조인 없이 하위 테이블만으로 검색을 완료할 수 있다.
내용을 정리하자면 ORM 신규 프로젝트 진행시 될 수 있으면 비식별 관계를 사용하고 기본 키는 Long 타입의 대리 키를 사용하는 것이 좋다. (Integer는 20억정도면 끝나기 때문에 문제가 있을 수 있음)
✅ 7.4 조인 테이블
데이터베이스 테이블의 연관관계를 설계하는 방법은 크게 2가지 이다.
- 조인 컬럼 사용 (외래 키)
- 조인 테이블 사용 (테이블 사용)
- 조인 컬럼 사용
테이블 간에 관계는 주로 조인 컬럼이라 부르는 외래 키 컬럼을 사용해서 관리한다.

- 라커를 선택적으로 입력 받는 상황에서 외래 키에 null을 허용하는 관계를 선택적 비식별 관계라 한다.
- 선택적 비식별 관계는 외래 키에 null을 허용하므로 outer join을 사용해야 한다.
- 관계를 맺는 일이 적다면 외래 키 값 대부분이 null로 입력
- 조인 테이블 사용
조인 컬럼을 사용하는 대신에 조인 테이블을 사용해서 연관관계를 관리한다.

- 연관관계를 관리하는 조인 테이블(MEMBER_LOCKER)을 추가하고 여기에서 관리
- 관리하는 조인 테이블 하나 추가와 조회시 조인 횟수 증가라는 단점이 있음
- 조인 테이블은 주로 다대다 관계를 일대다, 다대일 관계로 풀기위해 사용, 그렇지만 일대일, 일대다, 다대일 관계에서도 사용한다.
🔸 7.4.1 일대일 조인 테이블

일대일 관계를 만들려면 조인 테이블의 외래 키 컬럼 각각에 총 2개의 유니크 제약 조건을 걸어야 한다.
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@OneToOne
@JoinTable(name = "PARENT_CHILD",
joinColumns = @JoinColumn(name = "PARENT_ID"),
inverseJoinColumns = @JoinColumn(name = "CHILD_ID")
)
private Child child;
}
@Entity
public class Child {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
}부모 엔티티를 보면 @JoinTable을 사용했다. @JoinTable의 속성은 다음과 같다.
- name : 매핑할 조인 테이블 이름
- joinColumns : 현재 엔티티를 참조하는 외래 키
- inverseJoinColumns : 반대방향 엔티티를 참조하는 외래 키
if. 양방향으로 매핑하고 싶다면?
public class Child {
// ... 생략
// 추가
@OneToOne(mappedBy = "child")
private Parent parent;
}
🔸 7.4.2 일대다 조인 테이블
일대다 관계를 만들려면 CHILD_ID에 유니크 제약조건을 걸어야 한다.

@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@OneToMany
@JoinTable(name = "PARENT_CHILD",
joinColumns = @JoinColumn(name = "PARENT_ID"),
inverseJoinColumns = @JoinColumn(name = "CHILD_ID")
)
private List<Child> children = new ArrayList<>();
}
@Entity
public class Child {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
// ...
}
🔸 7.4.3 다대일 조인 테이블
다대일은 일대다에서 방향만 반대
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@OneToMany(mappedBy = "parent")
private List<Child> children = new ArrayList<>();
}
@Entity
public class Child {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
@ManyToOne(optional = false)
@JoinTable(name = "PARENT_CHILD",
joinColumns = @JoinColumn(name = "CHILD_ID"),
inverseJoinColumns = @JoinColumn(name = "PARENT_ID")
)
private Parent parent;
}
🔸 7.4.4 다대다 조인 테이블
다대다 관계를 만들려면 조인 테이블의 두 컬럼을 합해서 하나의 복합 유니크 제약조건을 걸어야 한다.

//부모
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@ManyToMany
@JoinTable(name = "PARENT_CHILD",
joinColumns = @JoinColumn(name = "PARENT_ID"),
inverseJoinColumns = @JoinColumn(name = "CHILD_ID"))
private List<Child> children = new ArrayList<>();
}
//자식
@Entity
public class Child {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
}
✅ 7.5 엔티티 하나에 여러 테이블 매핑
잘 사용하지는 않지만 @SecondaryTable을 사용하면 한 엔티티에 여러 테이블을 매핑할 수 있다.

@Entity
@Table(name = "BOARD")
@SecondaryTable(name = "BOARD_DETAIL",
pkJoinColumns = @PrimaryKeyJoinColumn(name = "BOARD_DETAIL_ID"))
public class Board {
@Id @GeneratedValue
@Column(name = "BOARD_ID")
private Long id;
private String title;
@Column(table = "BOARD_DETAIL")
private String content;
}Board 엔티티는 @Table을 사용해서 BOARD 테이블과 매핑했다. 그리고 @SecondaryTable을 사용해서 BOARD_DETAIL 테이블을 추가로 매핑했다.
@SecondaryTable 속성은 다음과 같다.
@SecondaryTable.name: 매핑할 다른 테이블의 이름@SecondaryTable.pkJoinColumns: 매핑할 다른 테이블의 기본 키 컬럼 속성
더 많은 테이블을 매핑하려면 @SecondaryTables를 사용하면 된다.
@SecondaryTables({
@SecondaryTable(name="BOARD_DETAIL"),
@SecondaryTable(name="BOARD_FILE")
})참고로 @SecondaryTable을 사용해서 두 테이블을 하나의 엔티티에 매핑하기 보다는 테이블당 엔티티를 각각 만들기를 권장한다.
이 방법은 항상 두 테이블을 조회하므로 최적화하기 어렵다.